语言技术平台(Language Technology Platform, LTP)
自然语言处理研究所历时十余年研发了一整套高效、高精度的自然语言处理系统 – 语言技术平台,其已成为中文自然语言处理领域影响力最大的开源基础技术平台。
该平台集词法分析(分词、词性标注、命名实体识别)、句法分析(依存句法分析)和语义分析(语义角色标注、语义依存分析)等多项自然语言处理子系统于一体,有效解决了自然语言处理技术入行门槛高,准确率、效率偏低,缺少共享数据和程序资源,重复开发现象严重,结果可视化差,错误分析困难,较难真正支持各类应用研究等众多问题。
目前,已被包括清华大学、北京大学、CMU等国内外众多大学及科研机构在内的600余家研究单位签署协议使用。同时,向百度、腾讯、华为、讯飞等多家知名公司收费授权,累计创造直接经济价值两千余万元。还是最早以“云计算”方式对外提供了中文自然语言处理服务,并将其命名为“语言云”,目前语言云累计注册的厂商及开发者已超过1万个。
平台中多项核心算法在国际评测中获得优异成绩,其中包括3次CoNLL(2009、2018、2019)国际句法和语义分析评测第一名。CoNLL系列评测是自然语言处理领域权威评测,每年组织一次,吸引了斯坦福、UIUC、Facebook等众多国际知名学术机构参加。
2010年,语言技术平台获得了中国中文信息学会颁发的“钱伟长中文信息处理科学技术奖”一等奖;2016年获黑龙江省科技进步一等奖。
LTP网站链接:http://ltp.ai/
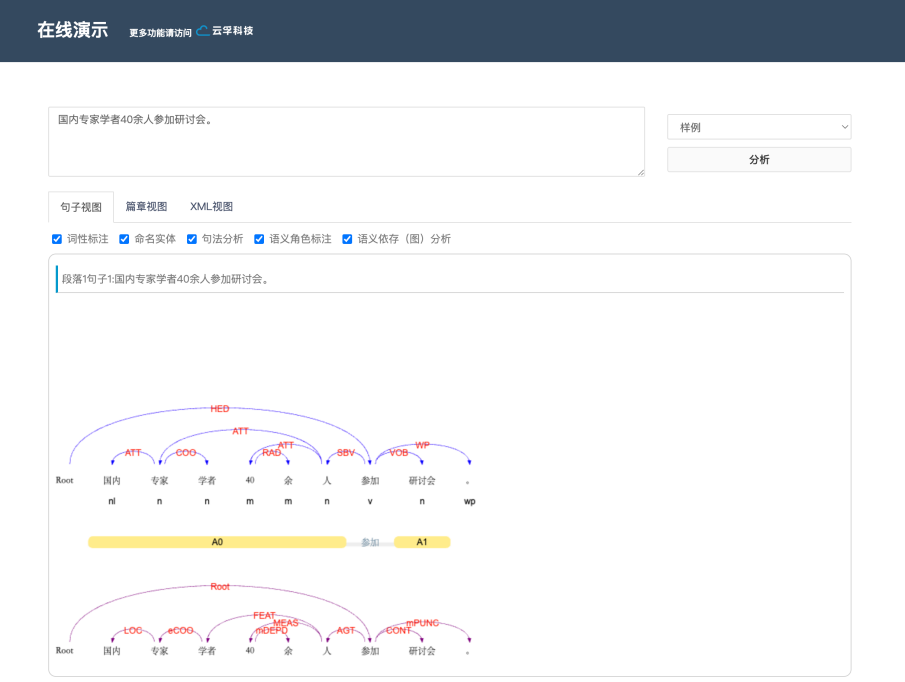
LTP演示图
《大词林》
《大词林》是由哈尔滨工业大学自然语言处理研究所推出,由秦兵教授和刘铭教授主持开发,是一个自动构建的大规模开放域中文知识库。自2014年11月推出第一版《大词林》,《大词林》共经历了两次大的版本变化。第一版的《大词林》包含了自动挖掘的实体和细粒度的上位概念词,类似一个大规模的汉语词典,其特点在于自动构建、自动扩充,细粒度的上下位层次关系。第二版的《大词林》引入了实体的义项和关系、属性数据,将每一个实体的义项唯一对应到细粒度的上位词概念路径,让《大词林》中实体的含义更加清晰。
相比于传统的开放域实体知识库,《大词林》的特点在于:1)构建不需要领域专家的参与,而是基于多信息源自动获取实体类别并对可能的多个类别进行层次化,从而达到知识库自动构建的效果。2)其数据规模可以随着互联网中实体词的更新而扩大,很好地解决了以往的人工构建知识库对开放域实体的覆盖程度极为有限的问题。3)每一个实体的义项均能够唯一对应到细粒度的上位词概念路径且具有丰富的实体和关系数据,能够更加清晰明确的展示实体的含义。
目前《大词林》2.0版已拥有实体30,102,845,上位词182,079,优质的实体上下位关系对15,577,846,属性-值对79,568,791,关系(属性)数436,961。《大词林》已被科大讯飞、腾讯、奇虎360等多所公司以及高校付费使用,已被科大讯飞、腾讯、奇虎360等多所公司以及高校付费使用。
《大词林》系统网站链接:www.bigcilin.com
《大词林》演示图
事理图谱
研究所首创地提出事理图谱概念,将实体和事理有机融合,构建了以事件和事理为核心、事理逻辑关系为边的知识库,解决了现有知识图谱体系性缺失问题。并提出了事理图谱和大模型的协同增强机制,实现了基于大模型的通用、动态事理知识更新,并利用事理知识增强技术提升了大模型的推理可靠性和完整性。相关研究内容获黑龙省科技进步一等奖,获批国家重点研发计划“战略性科技创新合作”重点专项,并获得ACL 2024杰出论文奖等。
金融事理谱图网站链接:http://eeg.8wss.com/main
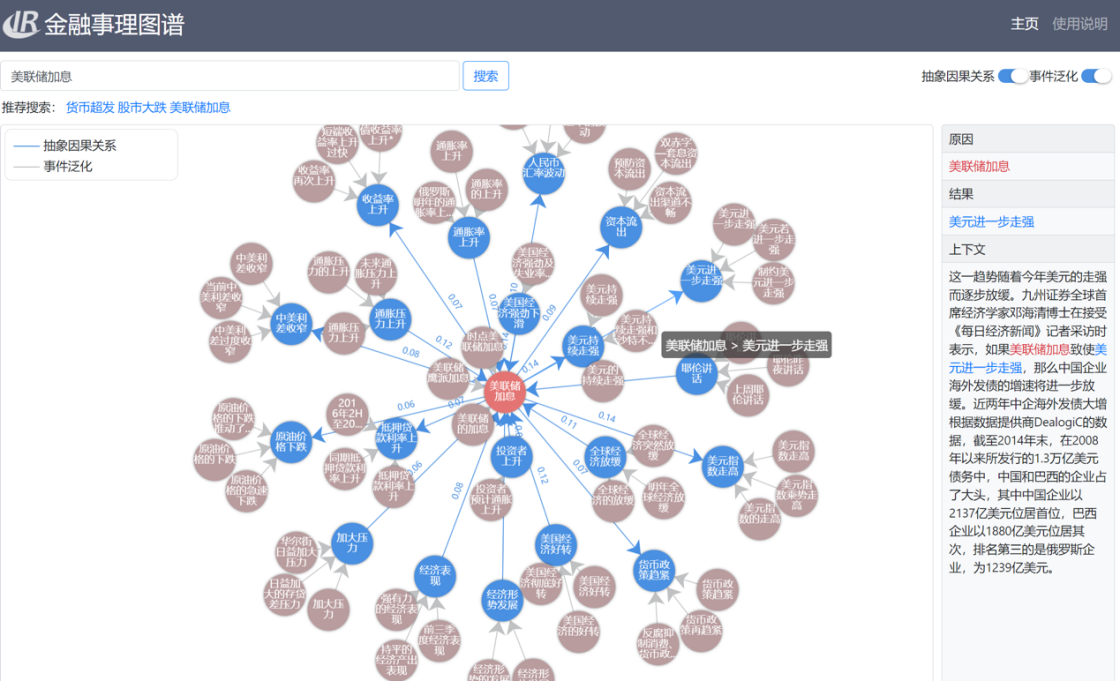
事理图谱演示图
医学知识图谱CPubMed-KG
构建的全国最大的开放大规模中文医学知识图谱,服务于全国近200个团队。该知识图谱中的知识来源于中华医学会旗下300余万篇高质量中文核心医学期刊,并及时更新,其关系与实体规范与主流中文医学规范兼容,实体、关系的来源明确,可回溯、易判别,并在以疾病为中心的三元组规模上达到了460万。支撑了由北京协和医院、重庆医大附属儿童医院(国家临床中心)分别牵头的科技部创新2030-“新一代人工智能”重大项目“疑难罕见病人工智能辅助诊断技术研究与临床应用”和“儿科疾病复杂循证知识图谱构建研究”的课题、子课题研究工作。
医学知识图谱CPubMed-KG的网站链接:https://cpubmed.openi.org.cn/graphwiki
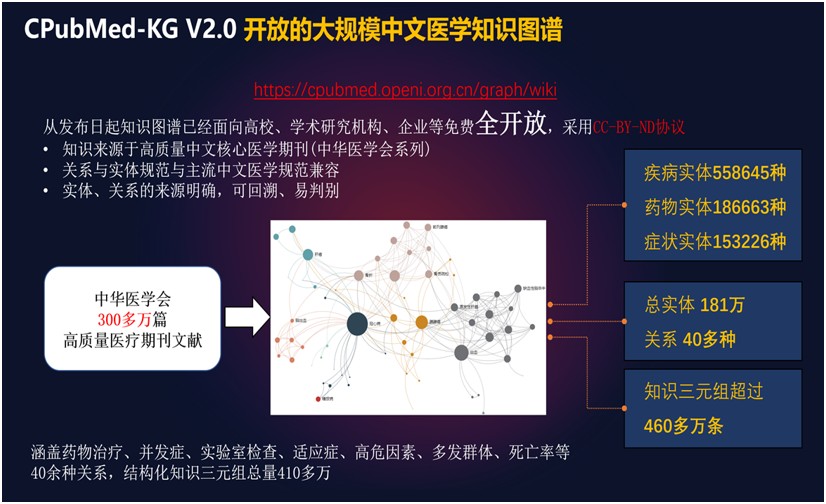

医学知识图谱场景
“珠算”代码大模型
由自然语言处理研究所研发,以2.7B参数首次在代码与通用能力上全面超越了国内外同量级代码大模型。核心技术覆盖了数据清洗、预训练、后训练以及轻量化部署等大模型完整技术栈,所有技术全面自主可控。提出了一种继续预训练技术,在提升编程能力的同时,有效克服了在通用知识上的灾难性遗忘问题。以珠算代码大模型为基座的珠算-VSCode插件和珠算-SQL系统,扩展了代码自动生成应用生态,进一步提高了编程效率。
珠算-SQL系统网站链接:https://huozi.8wss.com/abacus-sql/
“珠算”代码大模型演示图
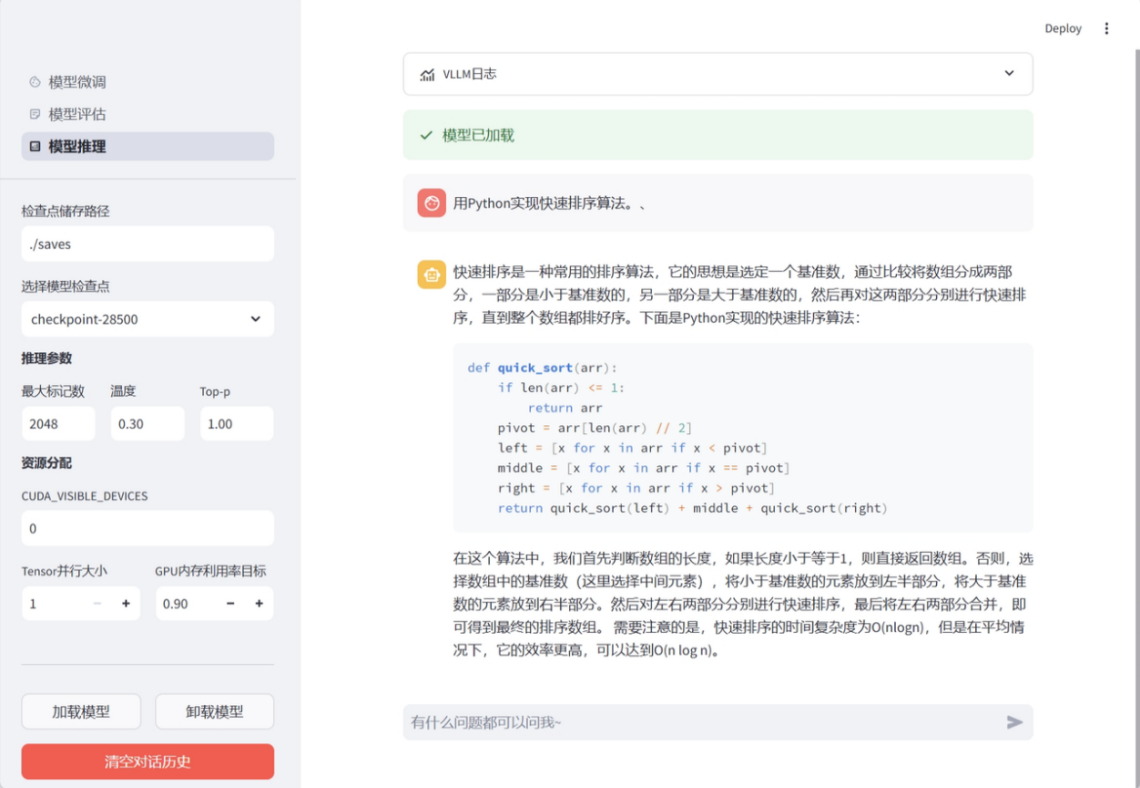
“巧板”情感陪伴大模型
“巧板”大模型旨在帮助K12中小学生应对学习、生活、人际交往等方面的挑战,特别是他们在这些场景中可能遇到的情绪问题。系统包含四大模块,分别为共情陪伴、情绪疏导、角色化陪伴以及心理疾病早期预警等。该系统通过共情技术与用户互动,构建了数十万级的高质量共情对话数据和共情策略偏好数据,从而能够使得模型灵活选择并应用相应的共情陪伴策略,精准识别用户的情绪变化并进行有效的情绪疏导和心理干预,使干预手段更具针对性与实效性。目前,巧板部分功能已融入进科大讯飞学习机的“AI心理伙伴”中,并已与哈尔滨市第一专科医院开展合作,全面实现AI赋能心理咨询。
“巧板”情感陪伴大模型2.5网站链接:http://qiaoban.hit-scir.com
“巧板”功能演示图
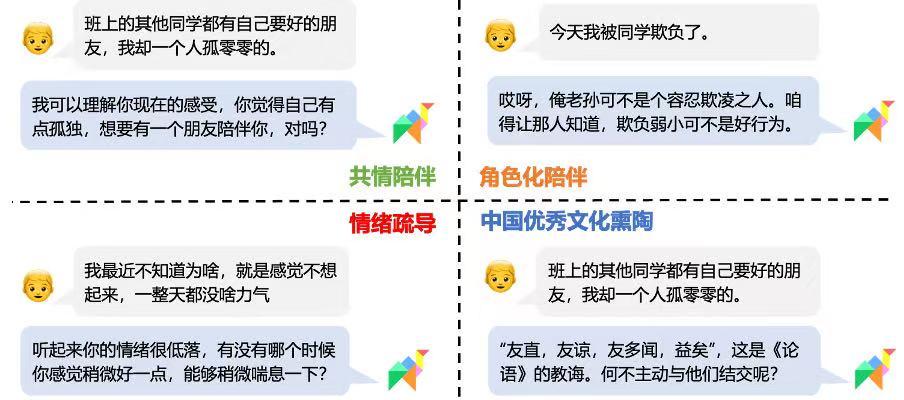
“风筝”航天大模型
风筝大模型基于Qwen2系列基座模型研发,是国内首个中文航天科普领域大模型,在航天知识问答准确性方面已达国际领先水平。其通过在23万条高质量航天相关数据上进行多阶段后训练获得,具有丰富的领域知识和强大的用户指令理解能力。基于该模型搭建的“航天科普助手”已正式上线至国内著名的航天爱好者社群网站“卫星百科”首页,为青少年提供权威、便捷的航天知识服务。
“风筝”航天大模型链接:https://175.27.128.14:5052/
“风筝”航天大模型演示图
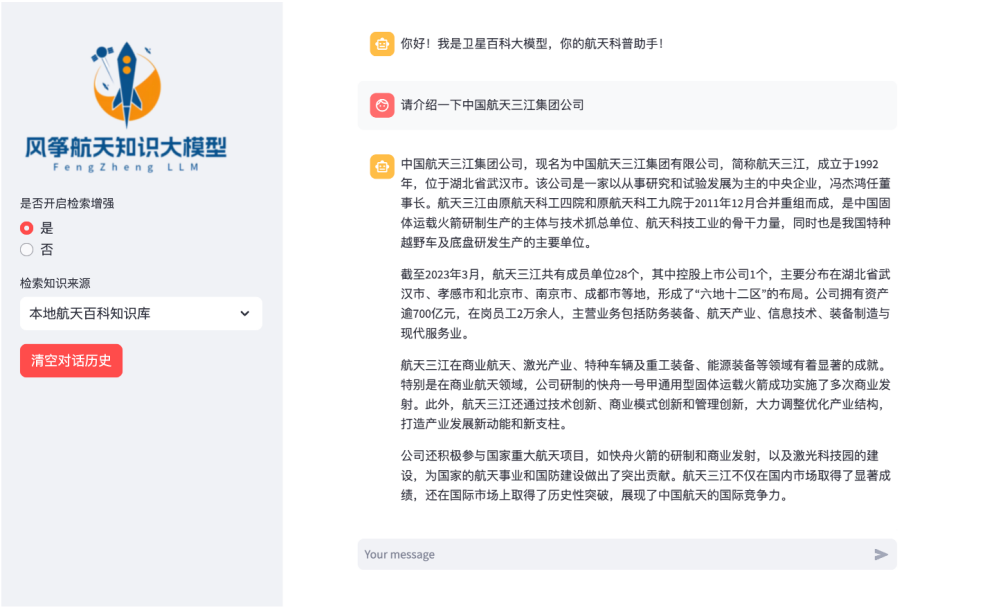
“本草”医学大模型
本草大模型是中国第一个医学大模型,在国际著名开源社区GitHub上获得4.7K多星标,提出的领域“知识微调”方法,被华为、腾讯、讯飞、京东方、中移动等企业使用。本草大模型相关技术发表CCF A/B类论文10篇,申请专利8项,入选教育部高教司大模型名录,入选德本咨询(DBC)联合中国社会科学院信息化研究心(CIS)、《互联网周刊》(CIW) 等组织发布的“2023中国大模型TOP70”榜单第27名,为仅有的3个高校研发的大模型之一。
“本草”医学大模型链接:https://huozi.8wss.com/
“本草”医学大模型演示图
人机融合会诊系统
围绕类人多轮协商的智能体动态自组织机理和面向诊疗决策生成的人机多方辩论机制两个核心科学问题,研究人机协同的细粒度医学知识挖掘技术,探索医学知识的条件表达,支持复杂疾病的诊断推理;研究非确定性的辩论要素挖掘和多方多轮辩论流程控制等关键技术,实现人机融合的诊疗决策;研究影像、病历等异构智能体的会诊自组织策略,突破条件受限下的智能体自学习增强技术,及基于模仿和生成的自组织增强技术;研究医学本体和语言联合理解,少样本文本理解以及对话理解与生成等关键技术,支持多方会诊的交互与辩论;并针对肝胆胰疑难病症实现人机多方会诊平台。
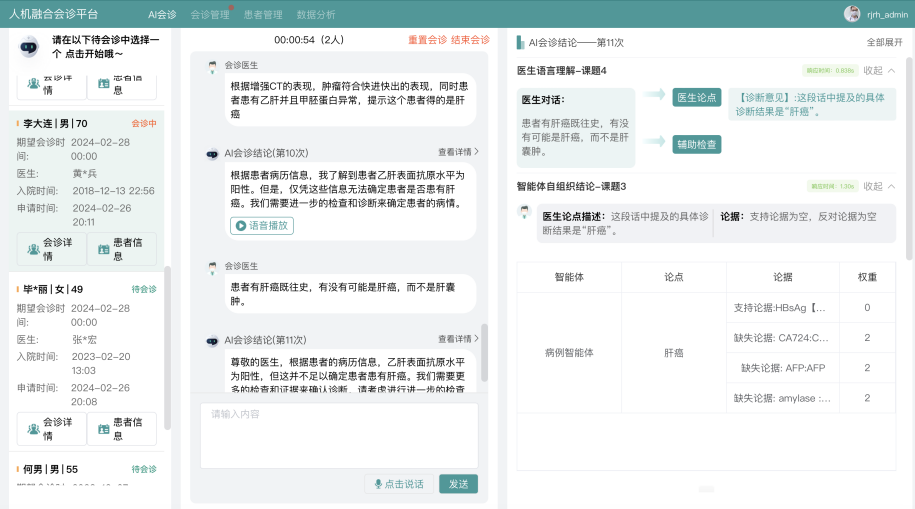
肝胆胰人机融合医疗会诊系统演示图
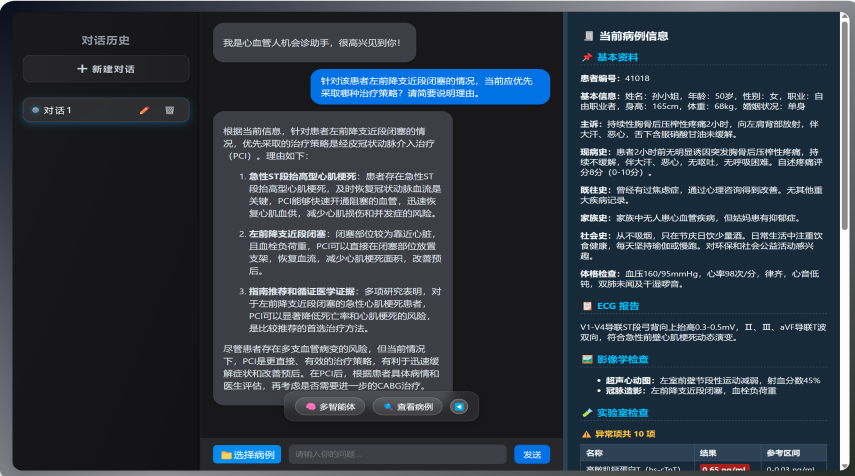
心血管人机融合医疗会诊系统演示图
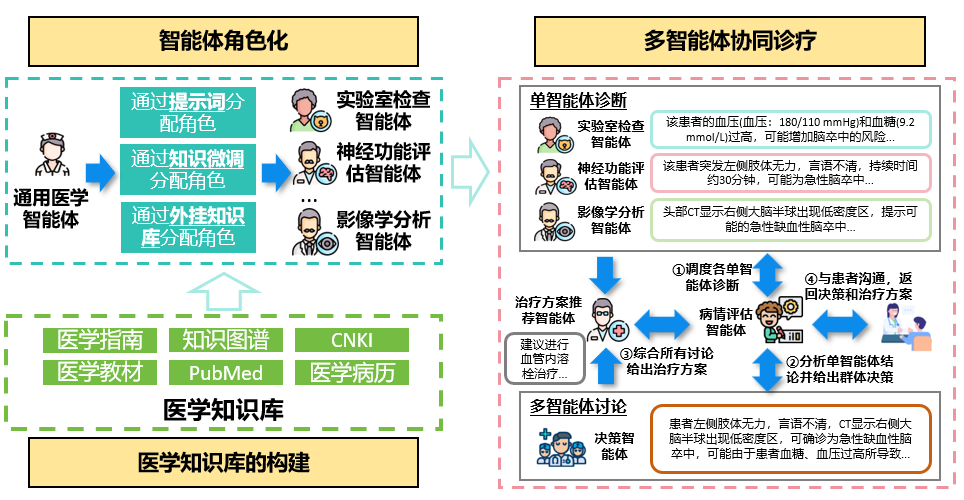
脑卒中人机融合医疗会诊系统架构图
具身机器脑
自然语言处理研究所的具身智能脑系统搭载于Aloha机器人之上,基于研究所自研的“活字”大模型,能够与人交流、接收指令,并自主规划自身的行为、操作本体运动,以此来完成各种任务,可实现自主导航及避障、自主按/进电梯、语音互动及抓握动作等。研究所研制的软硬一体具身机器脑,现可搭载多款异构机器人上,并操控其完成多种复杂任务。
“惊堂木”事实核查大模型
惊堂木是由自然语言处理研究所开发的虚假信息检测系统,旨在应对自媒体和AIGC 时代下的虚假信息检测挑战。“惊堂木”利用一个包含10多万个虚假信息样本的大规模数据案例库来训练专用的AI模型,从而更准确地识别出虚假信息。系统还引入了“慢思考”策略,在判断信息真假时,它不会草率地下结论,而是逐步分析、查证相关信息,同时配合各种工具进行辅助判断,可以细粒度地针对待检测信息的每个语义片段进行事实核查。该系统不仅能分析文字,还能识别图片、音频等多种信息类型,从而更全面地判断一个信息是否可信。此外,它还能进行事实核查、谣言识别、评估信息来源是否可靠,甚至支持多轮对话中的虚假信息识别。最终目标是防止虚假信息带来的社会风险,保护国家的稳定和安全。
“惊堂木”小程序链接:


惊堂木原理图
辩论式决策机(为舆论引导服务)
本服务旨在解决政府、高校、媒体等决策主体面对复杂事件时,因信息庞杂、视角多元、真伪难辨而产生的决策片面性问题。其核心目标是实现基于人机协作式辩论的复杂事件决策,即先通过多智能体意见融合生成决策意见,再与人类专家辩论以提升决策准确性。平台创新性地提出了条件事理图谱,通过构建决策领域细粒度条件事理体系,建模事件到决策的演化条件,实现复杂决策环境下事件动态演化过程的精确建模;此外,本平台还采用了由虚假信息检测智能体、认知争夺点智能体等多智能体构建的智能体感知系统获取可用信息,并结合多智能体自组织自学习的意见融合机制生成初步决策意见;最后,本平台提出可批判性生成决策意见的人机协同方法,通过人机辩论的形式生成决策意见,在与人类专家展开迭代论证和辩论的过程,在不同观点与方案之间进行权衡和对比,从而筛选出最佳行动方案。不仅实现了对复杂事件的全面分析,更在“认知”层面提高了决策的深度、广度、准确度。
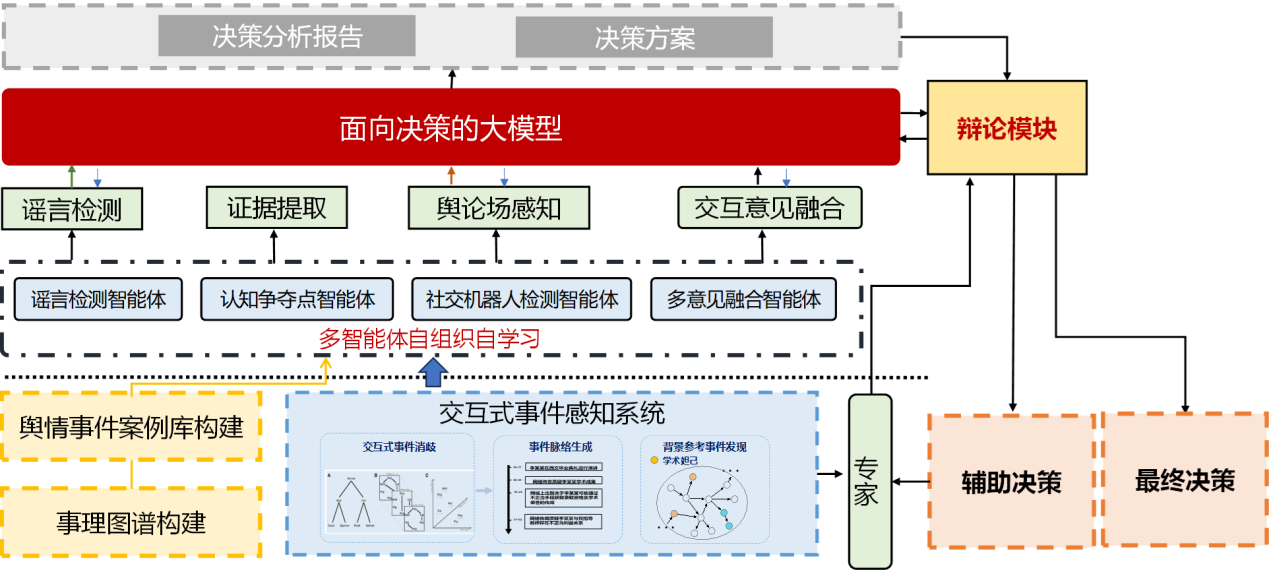
辩论式决策机系统架构图